Get a Movie's Details From IMDb
Update: The code used here doesn’t work anymore since IMDB’s last design update. The values were optained by web scraping the pages, and this depended a lot on the design of the site remaining reletively the same. Sorry for the inconvenience.
A while back when I was developing MoviePlay (a movies database) I wanted to allow the user to get the movie’s details from IMDb (The Internet Movie Database) instead of having him/her enter it manually. IMDb does not provide a way for developers to use their data, so I wrote the code below to screen scrape or web scrape the details from the movie’s page. It gets the title, director, genre, release year and tag line of the movie as well as the thumbnail.
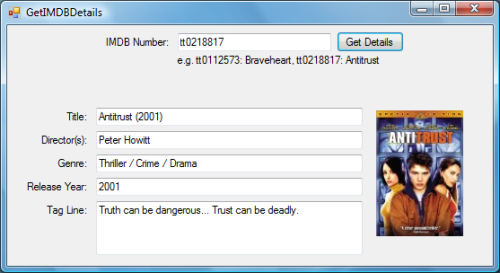
The first group of fields in the code below will be used for scraping. _SiteTitle contains the URL with out the movie’s number, so concatenating it with _IMDBNo will get the full URL of the movie. _FileContent will contain the raw HTML of the page. And htmlCodes is an HTMLCodes object used to remove the HTML tags. The Constructor just initializes _IMDBNo with the number passed by the user, downloads the HTML page into _FileContent, and initializes htmlCodes.
private string _SiteTitle = "http://www.imdb.com/title/";
private string _IMDBNo;
private string _FileContent;
private HTMLCodes htmlCodes;
private string _MovieTitle;
private string _Director;
private string _Genre;
private string _ReleaseYear;
private string _TagLine;
private Image _thumbnail;
public IMDBScraper(string IMDBNo)
{
_IMDBNo = IMDBNo;
//download the whole page, to be able to search it by regex
string URL = _SiteTitle + _IMDBNo + "/";
StreamReader sr = new StreamReader(new WebClient().OpenRead(URL));
_FileContent = sr.ReadToEnd();
htmlCodes = new HTMLCodes();
}
Scraping is done in the GetInfo method. I used regular expressions to get the data from the raw HTML. I got the movie’s title from the HTML Title tag, and for the rest I filtered the Body tag for the fields’ descriptions. For example to get the release date of the movie I searched for the Date .*.
public void GetInfo()
{
//scrape the movie title
string titlePattern = "<title>.*</title>";
Regex R1 = new Regex(titlePattern,
RegexOptions.IgnoreCase | RegexOptions.IgnorePatternWhitespace);
if (R1.Matches(_FileContent).Count > 0)
{
_MovieTitle = R1.Matches(_FileContent)[0].Value;
//remove the beginning title tag <title>
_MovieTitle = _MovieTitle.Substring(7);
//remove the ending title tag </title>
_MovieTitle = _MovieTitle.Substring(0, _MovieTitle.Length - 8);
_MovieTitle = htmlCodes.ToText(_MovieTitle);
}
//scrape the director
string directorPattern = "Director[s]*:.* [^\\>]* \\s*> \\s* [^\\<]* ";
R1 = new Regex(directorPattern,
RegexOptions.IgnoreCase | RegexOptions.IgnorePatternWhitespace);
if (R1.Matches(_FileContent).Count > 0)
{
_Director = R1.Matches(_FileContent)[0].Value;
_Director = (_Director.Split('>')[2]).Trim();
}
//scrape release year
string releaseYearPattern = "Date:.* [^\\>]* \\s*> \\s* [^\\<]* ";
R1 = new Regex(releaseYearPattern,
RegexOptions.IgnoreCase | RegexOptions.IgnorePatternWhitespace);
string releaseYear;
if (R1.Matches(_FileContent).Count > 0)
{
releaseYear = R1.Matches(_FileContent)[0].Value;
R1 = new Regex("\\d{4,4}",
RegexOptions.IgnoreCase | RegexOptions.IgnorePatternWhitespace);
_ReleaseYear = R1.Matches(releaseYear)[0].Value.Trim();
}
//scrape movie genre
string genrePattern = "Genre.*";
R1 = new Regex(genrePattern,
RegexOptions.IgnoreCase | RegexOptions.IgnorePatternWhitespace);
string genre;
if (R1.Matches(_FileContent).Count > 0)
{
genre = R1.Matches(_FileContent)[0].Value;
MatchCollection genreResults = R1.Matches(_FileContent);
string[] genreArray = genreResults[1].ToString().Split('>');
for (int C = 0; C <= genreArray.Length - 1; C++)
{
string seperater = "";
if ((C % 2 != 0) & (genreArray[C].Contains("more") == false))
{
if (_Genre != "" & _Genre != null)
seperater = " / ";
_Genre += seperater + genreArray[C].Substring(0,
genreArray[C].Length - 3);
}
}
}
//scrape movie tagline
string taglinePattern = "Tagline:.* [^\\>]* \\s*> \\s* [^\\<]* ";
R1 = new Regex(taglinePattern,
RegexOptions.IgnoreCase | RegexOptions.IgnorePatternWhitespace);
if (R1.Matches(_FileContent).Count > 0)
{
string tagLine = R1.Matches(_FileContent)[0].Value;
tagLine = tagLine.Split(new char[] { '>', '<' })[2];
_TagLine = tagLine.Trim();
}
else
{
_TagLine = "";
}
}
The GetPhoto method will get the thumbnail of the movie, which is on the top left corner in IMDb’s current website theme. To get the URL of the image I searched for an img tag that contains the movie’s title. This gets me the thumbnail image because IMDb always sets its alternate tag to the name of the movie.
public void GetPhoto()
{
string MovieName = _MovieTitle.Split(' ')[0];
//find the img tag containing the poster in the page
string RegExPattern = "<img [^\\>]* " + MovieName +
". [^\\>]* src \\s* = \\s* [\\\"\\']? ( [^\\\"\\'\\s>]* )";
Regex R1 = new Regex(RegExPattern,
RegexOptions.IgnoreCase | RegexOptions.IgnorePatternWhitespace);
MatchCollection matches = R1.Matches(_FileContent);
//find the link in the img tag and download the image and save it in the images folder
Regex R2 = new Regex("http.{0,}",
RegexOptions.IgnoreCase | RegexOptions.IgnorePatternWhitespace);
if (matches.Count > 0)
{
Match posterImageUrl = R2.Match(matches[0].Value);
Image posterImage = Image.FromStream(new WebClient().OpenRead(posterImageUrl.Value));
_thumbnail = posterImage;
}
}
Amged Rustom ASP.NET · WINFORMS · MONO 2.0